
Hadoop集群从180到1500,携程大数据实践之路
携程大数据平台现状
平台规模
2015年我刚加入携程的时候,它的Hadoop集群规模还仅有约180台,现在已经发展到超过1500台,也就是8倍的提升。同时每天的数据增量在200T以上,调度任务数9万,运行的实例超过18万,其中80%的作业都运行在SparkSQL上。 这些调度任务转换成底层任务大概是MR Job 27万,Spark Job 9万。实时方面我们现在支持Jstorm和Spark-streaming,整个集群规模100以上。
平台架构

上图为我们的平台架构。底层是自动化运维和监控;中间层是少量开源的大数据基础架构,分为批量计算框架和实时框架,批量部分的底层基于hadoop,在此之上的ETO主要是用Hive和Spark,另外还有Presto和kylin;平台最上层被划分为4个系统,开发平台Zeus、查询平台ART、AI开发和管理平台,以及实时数据平台Muise。
假如单从界面上来看muise就像一个管理平台,客户可以通过它做少量提交。但其实我们还对Sprak进行了封装,并提供自己的library。这是为了限制并发资源的使用,让客户可以控制并发资源,同时能够触发外部报警。【大数据开发学习资料领取方式】:加入大数据技术学习交流群458345782,点击加入群聊,私信管理员就可免费领取
系统 “走马观花”
数据开发平台总览
我们的开发平台分为5个系统,最主要的是调度系统Zeus。Datax数据传输系统用于给客户提供快捷配置的界面,客户操作完成后任务会被提交给Zeus。
主数据管理系统会展现表的信息并分析Job和Job间的依赖关系,以及通过解析SQL获取整体序列。
数据质量系统中配置了少量质量校验的规则,在调度系统运行完成之后会触发质量检验任务,假如优先级较高的质量校验任务失败就会阻断主要调度任务执行。最后是统一的权限绑定系统,这部分较为简单就不多做赘述了。
今年新进展
AI平台
尽管今年我们在底层上也做了很多尝试,但本次主要还是讲AI相关的基础设备上的少量工作。
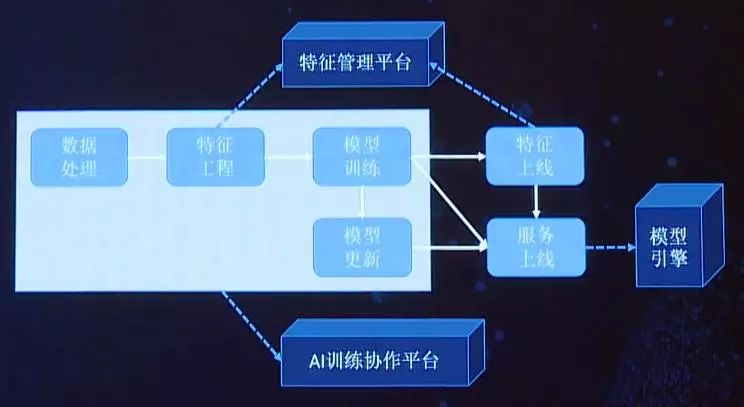
上图为简化的生命周期图,从数据解决到特征工程、模型训练、模型升级这样的过程,一般是AI训练的固定流程。当模型训练好并达到所制定的指标和要求之后,接下来就是上线,这部分分为特征上线和服务上线。
我们期望通过图中所示的3个平台来支持AI研发的整个生命周期。以特征管理平台管理所有的特征,能够支持特征工程,快速生成少量训练集和测试集,能够以更为简便的方式上线特征。
模型引擎主要用来cover服务上线过程,目标是让客户只要要开发必要的数据抽取逻辑等,其余的部分都可以通过配置的方式来形成上线服务,该板块后续计划会和我们公司的发布系统打通。而针对AI训练部分,我们希望通过AI训练协作平台来帮助客户更好的完成任务。
现阶段特征平台基本上开发完成,并已上线使用,AI训练平台刚刚开发完成,尚处于部署和测试阶段,而模型引擎仍在开发过程中。(截至演讲时间)
特征平台
特征平台的特征配置包括基础信息、数据源、计算逻辑、存储信息。我们的特征平台想做的是通过统一的SQL方式表示特征的计算逻辑,并以key value的形式存储。对于特征提取我们提供了对应API,客户可以通过特征ID和别名来获取相关特征。
特征提取完成后,客户会测试特征上线过程,平台为此提供了随机生成离线和实时任务的能力。离线任务主要是在Zeus的基础上添加少量传输作业。实时方面则会生成blink任务 ,由Kafka读取数据并解决后放到Spark上。
模型Engine
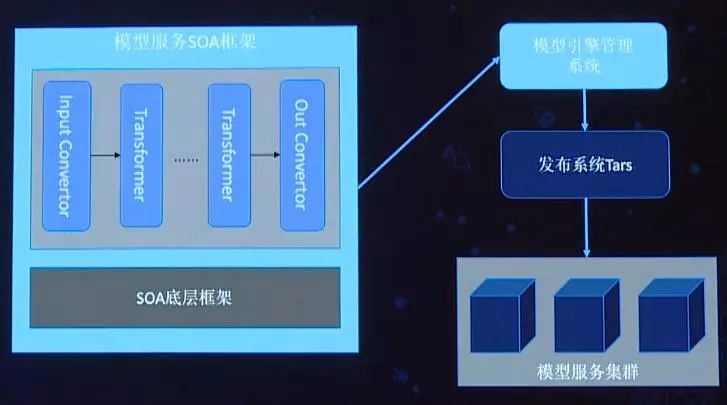
第一期的模型Engine会提供模型服务的SOA框架,其中包含自动转换的Input Convertor、Out Convertor。
模型服务的数据一般分为两种,通过服务直接输入的数据或者者放在Aerospike上的特征。客户要完成的是前面的transformer,做的更多的是根据输入的配置从Aerospike上获取特征,而后拼接在一起,再经过解决得到结果。后面的transformer基本上和训练的东西一样,只需通过配置的方式加载进来即可以了。
整个SOA框架由模型引擎管理系统负责管理,最后和我们的发布系统Tars集成发布到模型服务集群中。
大数据平台建设经验分享
选型准则
技术选型主要受需求成本、技术趋势、团队能力这3点所束缚。前两点相信大家都有考虑到,不过我要强调的是团队能力也非常重要,它并非一种静态的要求,而是动态的过程,需要领导者培养团队各方面能力以适应不断出现的新技术。【大数据开发学习资料领取方式】:加入大数据技术学习交流群458345782,点击加入群聊,私信管理员就可免费领取
就拿转向SparkSQL为例。不同于其余大厂早就用到了SparkSQL,我们去年年末才开始从Hive转到SparkSQL。一方面是由于SparkSQL在2.2之后处理了很多问题,稳固性上已经达到了我们的要求;另一方面是我们自身的条件也已成熟,团队中有一两位同学已经可以深入到Spark源码上处理问题。正是基于这种条件,我们才决定启动全面Hive转Spark的过程,这也是为什么说团队能力也很重要的起因。
案例 – 数据分析基础设备选型
对于数据分析基础设备选型我们首先面临的问题是,选择自建还是使用云服务,就我个人来看对于小规模没有特殊需求的数据分析,云服务是不错的选择。
其次是能否要用到Hadoop,这个主要看数据量及其增长情况,量不大的时候可以直接用数据库应对,要用Hadoop的话,现在一般采取HDFS加Spark的方式,数据存储格式用Parquet、Carbondata、ORC等。
另外还要考虑能否需要实时分析数据,目前这方面都是用的Spark-Streaming或者者Flink。最后假如对数据交互查询的速度要求不高,用Spark就够了,否则推荐使用Presto、kylin、ClickHouse。
如何“拥抱”新技术
有效和有限的分散——是美国历史上最成功的基金经理彼得林奇的投资准则之一。它的做法是以90%的资金重仓预先看好的股票,剩下的10%分散到多支股票上,并观察他们的趋势,而后将后续趋势较好的股票更新到重仓池中。
技术的投入其实也适用于这个准则。团队中大部分的资源应该先放在主要使用的技术上,对底层的系统来说要能够做到“代码级”维护。少部分的资源可以放在多种新技术或者是平台的“预备”/ POC上,假如靠谱,可以开始用在低优先级的系统或者项目上,最后也许会变成主要使用的技术。
“成长的烦恼”有什么
平台本身的增长一定会给底层的技术人员带来肯定的压力,主要表现在3个方面。
第一是在运维方面,系统规模的不断扩大,会使得运维系统越发复杂,并且种类也不断增多。
第二是开源系统的问题,开源是把“双刃剑”,它能帮你快速构建起相应的系统,但随着系统规模的增大,问题也会不断暴露出来。
第三是服务和支持方面,客户不断增长的“物质文化需求”与“短小精悍”团队之间的矛盾,临时的支持与问题排查工作也会变多。
处理运维问题最重要是在于自动化,而自动化的关键的有2个,一是要保证测试环境和线上配置一致,二是覆盖范围尽可能全,特别是用户端部分也要涉及到。监控方面比较简单,主要是监控重要指标并建立自动恢复的机制。
对于开源系统的使用,我认为还是要在思想上做好长期斗争的准备。最关键的是要建立“代码级”的维护能力,比方招聘时选择对技术有浓厚兴趣,能够沉下心来的同学;在底层团队通过各种层次的分享建立学习,研究的氛围。【大数据开发学习资料领取方式】:加入大数据技术学习交流群458345782,点击加入群聊,私信管理员就可免费领取
服务和支持问题的应对策略可以分为几点,包括从使用者的角度去设计产品,关注产品的易用性;控制推广的节奏;完善文档以及常见问题FAQ;加强BU数据开发的工程技术实力;短期的全员客服等。
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是摆设,本站源码仅提供给会员学习使用!
7. 如遇到加密压缩包,请使用360解压,如遇到无法解压的请联系管理员
开心源码网 » Hadoop集群从180到1500,携程大数据实践之路



