
通过Apache Spark建立共识集群
研究共识聚类以表示屡次聚类算法的共识,并分析聚类关于采样变异性的稳固性。
详情
在本文中,我们将探讨一种称为共识聚类的技术,以评估聚类算法针对数据集中的小扰动生成的聚类的稳固性。我们将回顾用Apache Spark机器学习库构建的示例应使用程序,以显示如何用K-means,Bisecting K-means和Gaussian Mixture(三种不同的聚类算法)能用共识聚类。
机器学习中的聚类分析[1]旨在根据数据点之间的类似性度量将数据划分为单独的,不重叠的集合。同一集群中的数据点必需尽可可以相近(类似),并且不同集群中的数据点必需尽可可以相距(不类似)。聚类分析在生物学,生物信息学,医学,商业,计算机科学和社会科学等各种科学学科中有很多应使用[1]。以下是少量例子。
- 聚类可使用于医学图像的像素分类,以辅助医学诊断[2]。
- 为了分析患者的预期寿命取决于他们属于哪一个群,[3],癌症患者的数据能根据某些属性(例如“区域节点阳性”和“阶段组群”)聚类为一组。
- 癌细胞的基因表达可通过聚类技术进行分析,以分析细胞结构并预测生存[4]。
许多不同的技术和算法可使用于聚类分析,其中[5]和[6]提供了极好的评论。
问题陈述
不同的聚类算法能为相同的数据集创立不同的聚类。在不同的执行过程中,即便是相同的算法也会产生不同的簇,例如因为随机启动。作为一个例子,我们从美国国家癌症研究所GDC数据门户网站下载了关于多形性成胶质细胞瘤(GBM)和低级别胶质瘤(LGG)患者的数据集,并用K均值聚类算法将它们分成三个聚类。
结果如图1.a,1.b所示,使用于两种不同的解决。
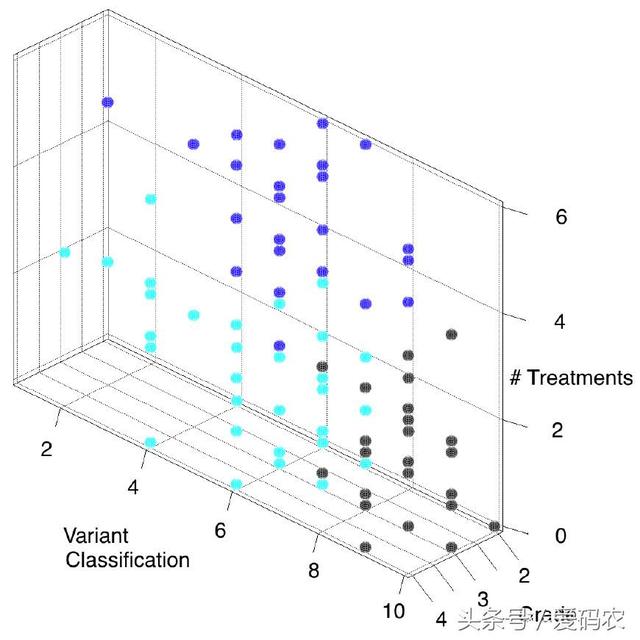
说明
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是摆设,本站源码仅提供给会员学习使用!
7. 如遇到加密压缩包,请使用360解压,如遇到无法解压的请联系管理员
开心源码网 » 通过Apache Spark建立共识集群
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是摆设,本站源码仅提供给会员学习使用!
7. 如遇到加密压缩包,请使用360解压,如遇到无法解压的请联系管理员
开心源码网 » 通过Apache Spark建立共识集群

