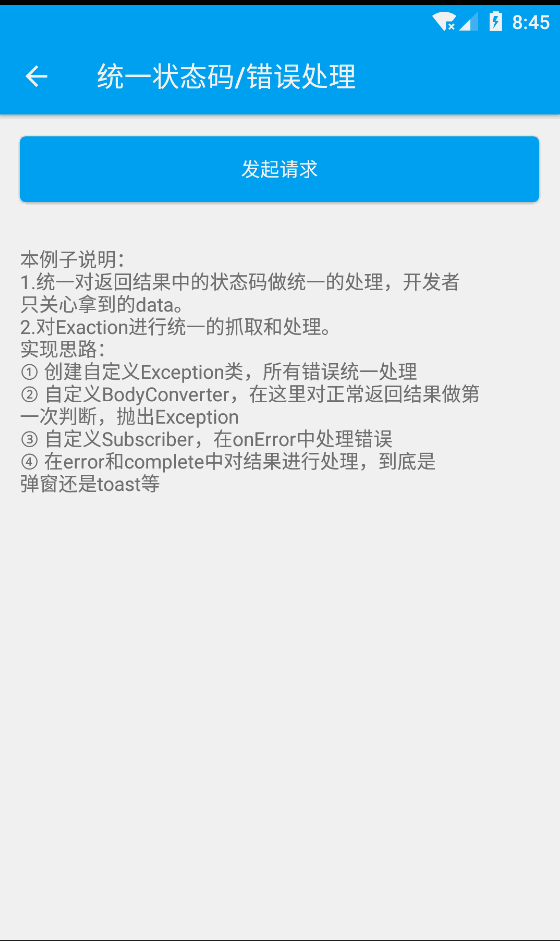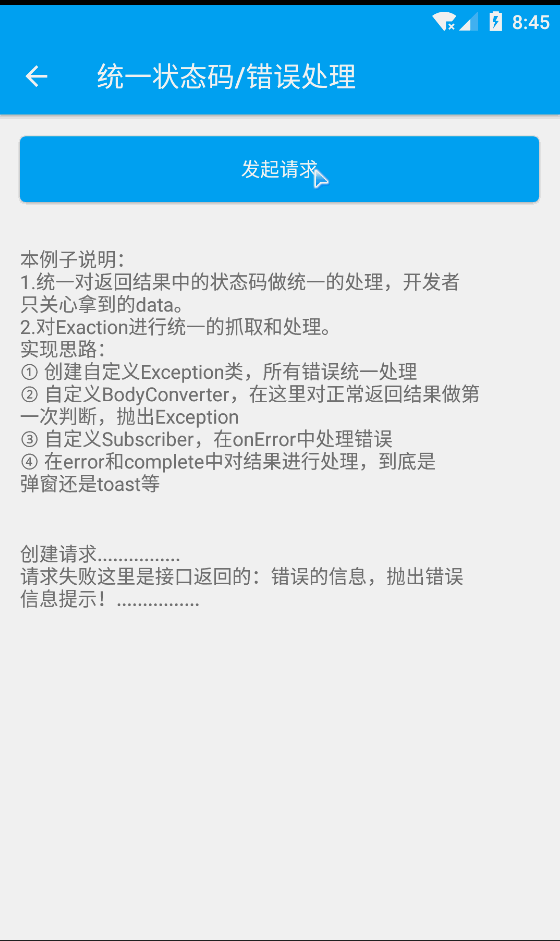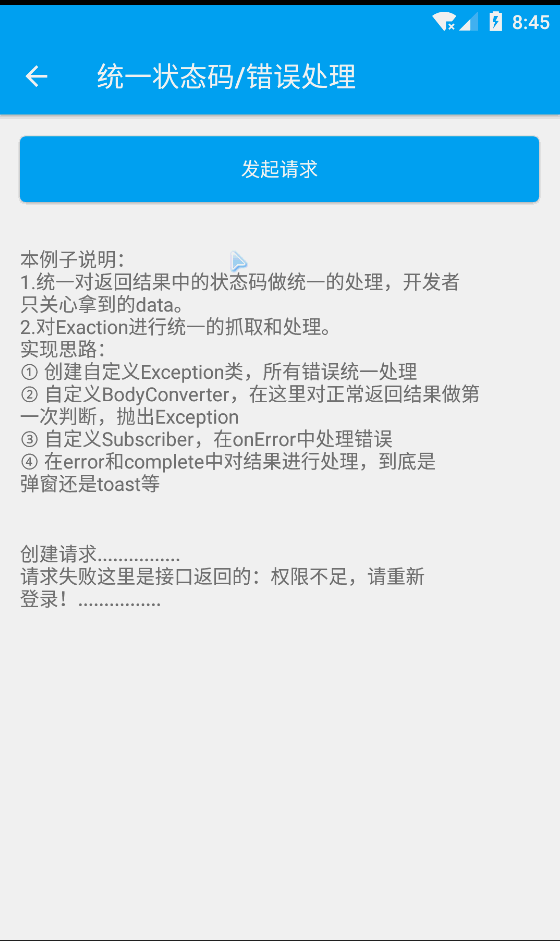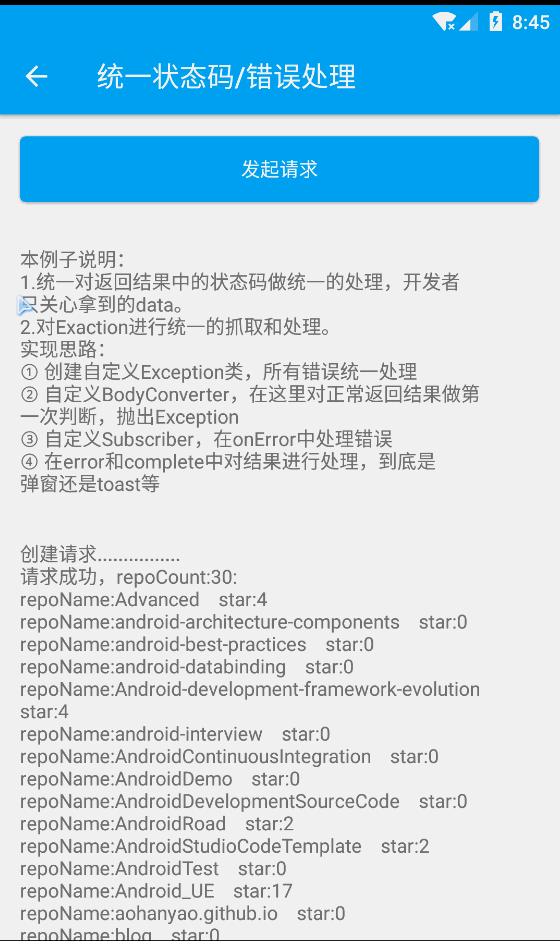
浏览器端的机器学习 tensorflowjs(5) 数据解决
 cover_002.png
cover_002.png
为了表现 TensorFlow.js 的性能优势,需要将数据转换成张量,同时来需要进行少量解决如洗牌和归一化,具体做法代码里见。
/** * 将输入数据转换可以喂入机器张量(tensors) * 对数据进行洗牌和标准化解决 */ function convertToTensor(data) { // 对数据进行操作包裹在一个 tidy 函数内。 return tf.tidy(() => { // Step 1. 对数据进行随机排序,这样便于多轮训练 tf.util.shuffle(data); // Step 2. 将数据转换为 Tensor const inputs = data.map(d => d.horsepower) const labels = data.map(d => d.mpg); const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]); const labelTensor = tf.tensor2d(labels, [labels.length, 1]); //Step 3. 将数据归一化,也就是将数据取值范围控制到 0 - 1 假如多特征可以消除正常差异性,便于训练 const inputMax = inputTensor.max(); const inputMin = inputTensor.min(); const labelMax = labelTensor.max(); const labelMin = labelTensor.min(); const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin)); const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin)); return { inputs: normalizedInputs, labels: normalizedLabels, // 返回 最小/最大界限 inputMax, inputMin, labelMax, labelMin, } }); }数据洗牌
tf.util.shuffle(data);每次训练数据前我们需要将数据的顺序打乱好处是更利于训练。由于在训练过程中,数据集通常被分成较小的子集,也就是所谓批次,模型在进行训练,让模型每次看到数据都是多样变化的。
转换为张量
const inputs = data.map(d => d.horsepower)const labels = data.map(d => d.mpg);const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);const labelTensor = tf.tensor2d(labels, [labels.length, 1]);我们这里数据有两个维度,也就是有两个特征,一个特征作为输入(马力),另一个是真实值(在机器学习中被称为标签)其实真实值也是数据一个特征。
而后将每个数组转换为一个 2d 张量。该张量的形状为 [num_examples, num_features_per_example]。其中 inputs.length 是样本数量,每个样本有 1 个输入特征(马力)。
数据标准化
const inputMax = inputTensor.max();const inputMin = inputTensor.min();const labelMax = labelTensor.max();const labelMin = labelTensor.min();const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));对数据进行归一化解决,也可以称为标准化解决。通过对数据进行缩放,让所有数据取值范围都在 0-1 这个范围。归一化其实很重要,好处消除不同取值范围特征之间差异性,同时模型更喜欢0 到 1 或者者 -1 到 1 这样的小数。
return { inputs: normalizedInputs, labels: normalizedLabels, // Return the min/max bounds so we can use them later. inputMax, inputMin, labelMax, labelMin,}之所以返回归一化缩放用到最大、最小值。用途两个,第一个是我们利用这些将数据进行复原,还有就是在预测时,可用这些值对新数据进行归一化解决。
说明
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是摆设,本站源码仅提供给会员学习使用!
7. 如遇到加密压缩包,请使用360解压,如遇到无法解压的请联系管理员
开心源码网 » 浏览器端的机器学习 tensorflowjs(5) 数据解决
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是摆设,本站源码仅提供给会员学习使用!
7. 如遇到加密压缩包,请使用360解压,如遇到无法解压的请联系管理员
开心源码网 » 浏览器端的机器学习 tensorflowjs(5) 数据解决