
C#之数据结构(下)
哈希表:
Hashtable. (也叫散列表)无序.
哈希表(Hashtable) ?HashSet.
由一对(key , value) 类型的元素组成的集合.
所有元素的 key 必需唯一.
key ->value 是一对一的映射,即根据key即可以立刻在集合中找到所需元素.
Hashtable方法:
Add(key, value)
根据key而不是根据索引查找,因而速度很快
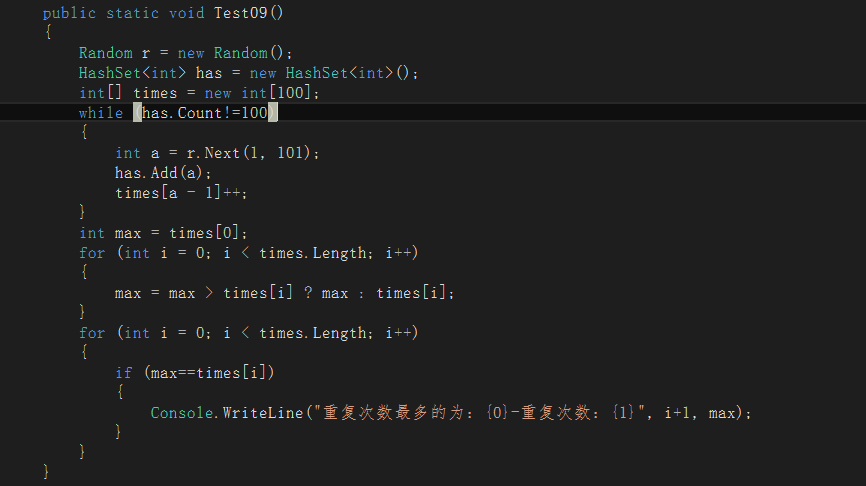
例子:
为哈希表追加不重复的100个值,且每个值都是1-100之间的随机数, 问哪个数字重复的次数最多,重复了多少次?
集合的迭代器
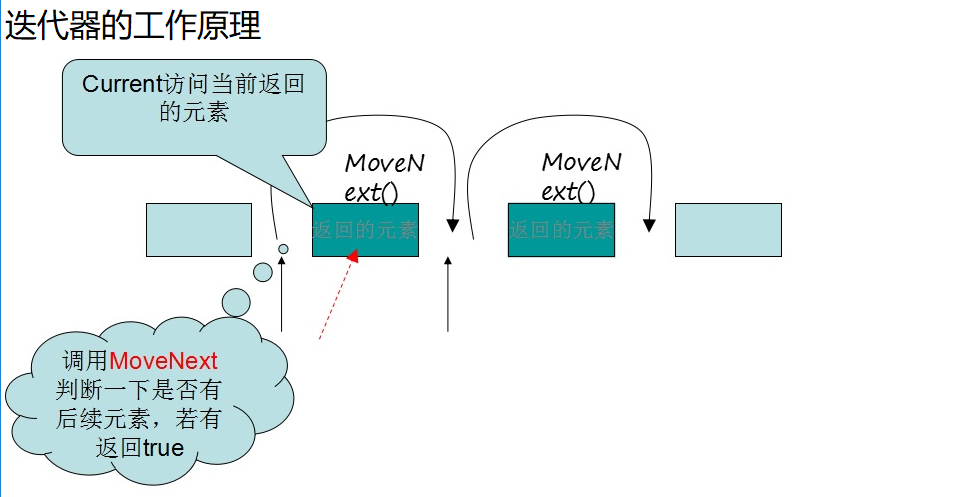
迭代器提供了对集合统一的遍历方案
foreach的本质:
注意:1.禁止在迭代中修改迭代变量!!!
?2.禁止在迭代中修改集合!!!
数组和集合的比较:
1.数组公告了元素类型,但集合没有,由于集合中所用元素都存储为对象。
2.数组的大小是固定的,不能添加和减少;而集合类可根据需要动态调整大小
检索元素的方式不同。
装箱和拆箱:
1. 装箱在值类型向引用类型转换时发生
object obj = 1;这行语句将整型常量1赋给object类型的变量obj; 众所周知常量1是值类型,值类型是要放在栈上的,而object是引用类型,它需要放在堆上;要把值类型放在堆上就需要执行一次装箱操作。
以上就是装箱所要执行的操作了,执行装箱操作时不可避免的要在堆上申请内存空间,并将堆栈上的值类型数据复制到申请的堆内存空间上,这一定是要消耗内存和cpu资源的。
2. 拆箱在引用类型向值类型转换时发生
object objValue = 4;
int value = (int)objValue;
上面的两行代码会执行一次装箱操作将整形数字常量4装箱成引用类型object变量objValue;而后又执行一次拆箱操作,将存储到堆上的引用变量objValue存储到局部整形值类型变量value中。
拆箱操作的执行过程和装箱操作过程正好相反,是将存储在堆上的引用类型值转换为值类型并给值类型变量。
装箱操作和拆箱操作是要额外耗费cpu和内存资源的,所以在c# 2.0之后引入了泛型来减少装箱操作和拆箱操作消耗。
泛型集合:
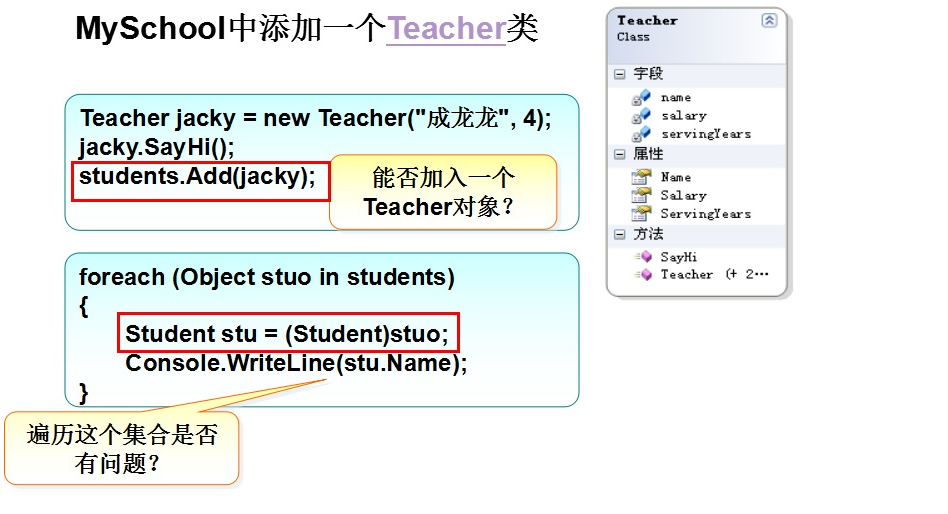

上面的情况是不带泛型的集合,我们可以看到,这种集合对象存储不易控制,类型转换容易出错。
下面的是带泛型的集合:
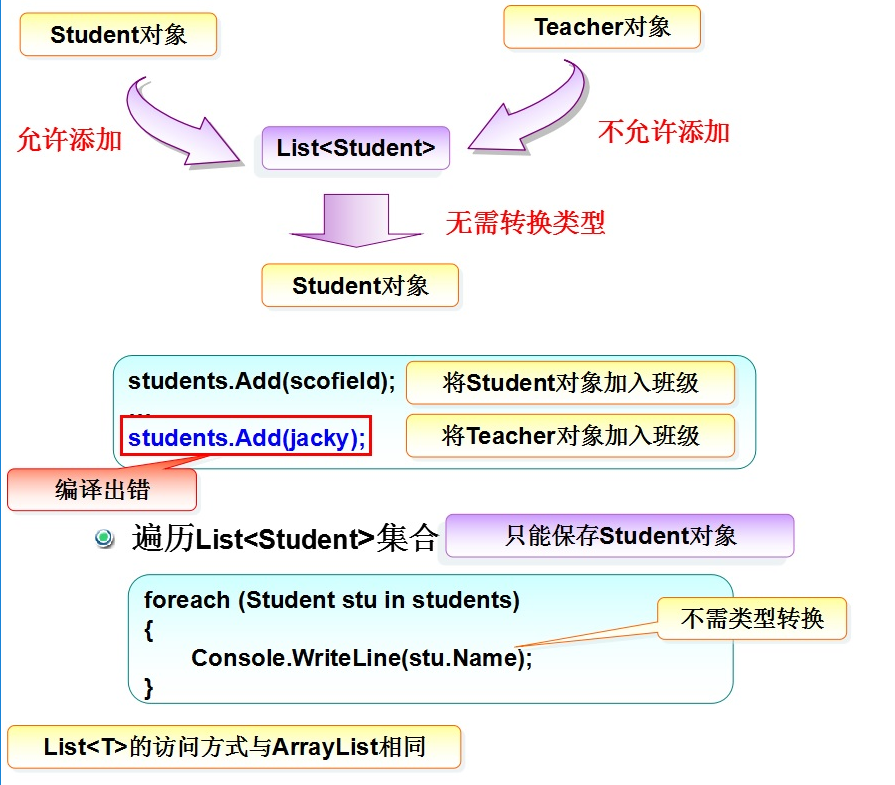
从上面两种情况我们可看出:
泛型集合可以束缚集合内的元素类型.
编译时检查类型束缚.
无需装箱拆箱操作.
加上using System.Collections.Generic;
List<T>,Dictionary<K,V> /<T>、<K,V>表示该泛型集合中的元素类型.
List<Student> students = new List<Student>();
利用List<Student>存储班级集合.

面试题:
请简述 ArrayList 和 List<Int>的主要区别:
1.ArrayList 不带泛型 数据类型丢失.
2.List<T> 带泛型 数据类型不丢失.
3.ArrayList需要装箱拆箱 List<T>不需要.
Dictionary<K,V>具备List<T>相同的特性
<K,V>束缚集合中元素类型
编译时检查类型束缚
无需装箱拆箱操作
与哈希表相似存储Key和Value的集合

泛型集合与传统集合相比类型更安全.
泛型集合无需装箱拆箱操作.
泛型的重要性:
1.处理了很多需要繁琐操作的问题.
2.提供了更好的类型安全性.
例子:
假定书籍的种类有5种,设计何种的数据结构可以达到快速查询某类所有书籍的功能(提醒:用Dictionary<K,V>)

判断一篇英文文章出现了哪些字母,以及每个字母出现的个数
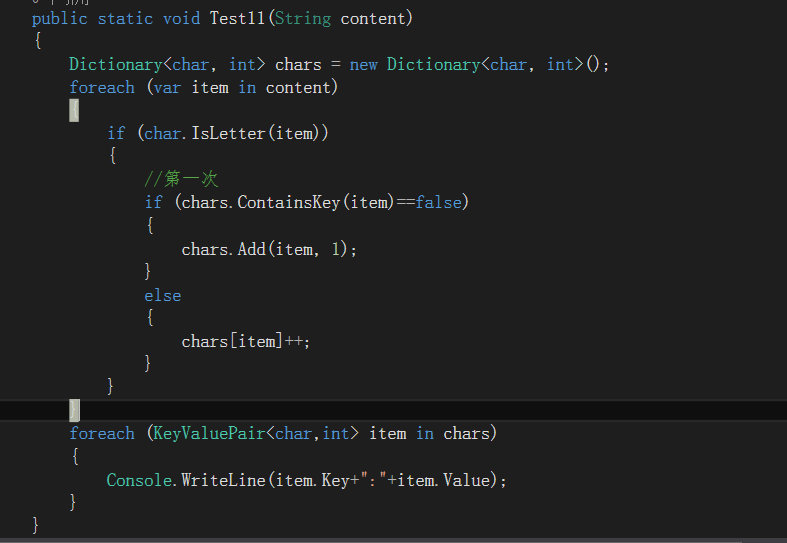
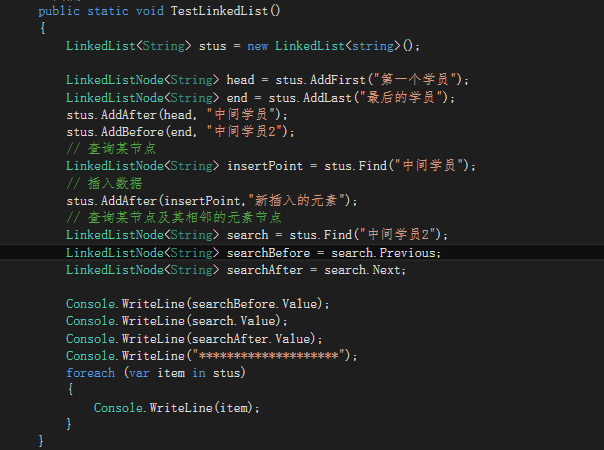
链表:
LinkedList<T>
生成和追加 ? LinkedList<string> linked = new LinkedList<string>();
linked.AddLast(“cat”);
linked.AddLast(“dog”);
linked.AddLast(“man”);
linked.AddFirst(“first”);
查找和插入? LinkedListNode<T>
LinkedListNode<string> node = linked.Find(“one”);
linked.AddAfter(node, “inserted”);
例子:
集合的排序:
集合中一律为对象类型.
所以集合需要排序的时候则必需两个对象需要有可比性.
IComparable与IComparer接口
为了能够对数据项进行排序,就要确定两个数据项在列表中的相对顺序,也就是要确定两个对象的“大小”关系。一般来说,可以通过如下两种方式来定义大小关系。
第一种方式是针对对象本身。为了使对象自己能够执行比较操作,该对象必需实现IComparable接口,即至少具备一个CompareTo()成员。
System.IComparable接口中有如下方法:
int CompareTo(object obj);
它根据当前对象与要比较的对象的“大小”返回一个正数、0或者一个负数。
第二种方式是提供一个外部比较器,能够比较对象的大小,并实现IComparer接口。
System.Collections.IComparer接口中有如下方法:
int Compare(object obj1, object obj2);
它根据第一个对象与第二个对象的“大小”返回一个正数、0或者一个负数。
许多类在进行排序和查找时,都要求提供这样的外部比较器。
例子:
1.通过 IComparable 来进行排序
 实现接口
实现接口

2. 通过IComparer来进行排序


说明
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是摆设,本站源码仅提供给会员学习使用!
7. 如遇到加密压缩包,请使用360解压,如遇到无法解压的请联系管理员
开心源码网 » C#之数据结构(下)
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是摆设,本站源码仅提供给会员学习使用!
7. 如遇到加密压缩包,请使用360解压,如遇到无法解压的请联系管理员
开心源码网 » C#之数据结构(下)



